Dec 15, 2018 · 6 minute read
We announced Cloud Native Application Bundles (CNAB) at DockerCon EU and Microsoft Connect just last week, and I spent a bunch of time talking to folks and anwsering questions about it at KubeCon too. As I’m heading home I thought it would be good to write down a few thoughts about what CNAB is. As I see it CNAB is two things:
- Formalisation of a pattern we’ve seen for multi-toolchain installers
- Commoditization of the packaging part of the infrastructure-as-code stack
Let’s take each of these in turn.
The explosion of APIs for infrastructure services has led to a corresponding explosion of tools to help you manage and orchestrate them. From API clients for individual projects (countless Kubernetes configuration management tools) to cloud-provider specific tools (CloudFormation templates, ARM templates) to high-level DSLs (Ansible, Terraform). Throw in the configuration complexity clock (so we have Pulumi in Typescript, Terraform with it’s own HCL DSL, too much YAML everywhere) and we have a lot of tool options. I posit this choice is a good thing, and that we’re never going to see everyone agree on one approach or another. One pattern that has emerged is packaging API clients as Docker images. lachlanevenson/k8s-kubectl has seen 5 million pulls, there are CloudFormation images on Hub that have millions of pulls, the official Terraform image has more than 10 million pulls. There are also lots of projects like terraform-ansible-docker which use multiple tools at the same time. CNAB is a formalisation of these patterns.
Commoditization of the packaging part of the infrastructure-as-code stack
There is a now familiar pattern when it comes to infrastructure-as-code tools, namely the introduction of a package format and some form of registry. Puppet and the Forge. Chef and the Supermarket. Ansible and Ansible Galaxy. Terraform and the Module Registry. Everyone basically creates a tar file with some metadata. Not all projects have done this, but most would probably benefit from doing so. Compose files, ARM templates, CloudFormation templates; all are shared predominantly as source artefacts which are copy-and-pasted around.
CNAB aims to commoditize this part of the stack and provide tools for anyone implementing something similar. It’s predominantly undifferentiated heavy lifting. No-one is competing based on the package metadata format so maybe lets build some agreement, some shared tooling and move on.
What has this got to do with Kubernetes?
One point that came up in a few conversations around CNAB was what this has to do with Kubernetes? Typically this came from people so deep into Kubernetes that all they can see is the Kubernetes API. If that’s you then you probably don’t need CNAB, especially at this early stage. You probably think in one of two ways when it comes to application of configuration:
- You like the package metaphor and you’re a big fan of Helm
- You don’t like the package metaphor and you use some other tool to access the Kubernetes API more directly
Back to our two original points. When it comes to a multi-toolchain installer, in the case of Kubernetes-only, you might not have multiple toolchains so this point is moot. Everything in your world is just the Kubernetes API.
When it comes to the second point around a standard for packaging, Helm already serves this need within the tight scope of Kubernetes. I fully expect to see (or hey, to build) a Helm plugin which will allow for wrapping a Helm chart in CNAB. There are a few advantages to CNAB support for Helm; a single artefact could include the desired Helm chart and it’s dependent charts and it could include all of the images in use within those charts. That single artefact can be signed and stored in a registry of your choise. But that’s mainly a case of incremental benefit to most Helm users. It’s also theorectical, CNAB is just a specifcation, so concrete things like a Helm plugin still need to be actually built.
What I would say to those that view everything through a Kubernetes lens is that not everyone does. CNAB is mainly for a messier world of multiple toolchains and multiple APIs.
Why you might care?
Depending on your role in the pantheon of software development you may care about one or both of the original points. You may care about them directly (especially if you’re a software vendor) or indirectly (because of what they allow us to collectively build for end-users.)
The story is pretty straightforward if you’re a software vendor. It’s very likely you’re shipping software to customers using multiple toolchains. Either you’re dealing with the complexity of asking customers to install particular tools and providing content for each (say asking users to first run some Terraform code and then run something else) or you’re struggling to get a large number of different teams to use the same tool and cram everything into it. Lots of vendors also have something that looks like a storefront for mixed content, or multiple stores for individual tools. Everyone is getting bored of supporting all the different formats, so a standard here appeals.
From the end user point of view the story is more about future potential. This is analogous to other standards. You might not have read or implemented anything against the OCI image or distribution spec, but you benefit from the compatability between all the different registries and runtimes. If you’ve built a multi-toolchain installer then you at least appreciate one of the problems CNAB aims to solve. But then you already have a point solution and the CNAB tooling is early here. You only benefit from commoditization of the format indirectly, and only if it’s actually adopted by multiple tools. But assuming it is widely adopted, in the future when a nifty new infrastructure as code tool comes along (say like Pulumi recently, or Terraform previously) then you’ll aleady know how to install applications defined using it if it implements the CNAB specifcation. You’ll already have CI/CD toolchains that accomodate CNAB. You’ll already have CNAB-compatible tools for storing and distributing bundles. The typical barriers to entry for yet another tool are reduced.
The importance of agreement
There is a risk with any effort like this, one that aims to solve a general problem at a low level, that the actual user need gets lost. This is one of those solutions which impacts tool builders directly, and end users somewhat indirectly. That means you have to be a certain type of developer to benefit from looking at CNAB today. But if you look at Docker App you’ll find a much more opinionated tool which just happens to implement CNAB under the hood, without exposing it to end users. The end user benefits there (sharing Compose-based applications on Docker Hub, a single artefact with the application definition and associated images) are much more concrete.
CNAB isn’t about one tool to rule them alI. It’s about building agreement between people and projects solving the same set of problems. That agreement means more time to focus on end users problems rather than undifferentiated heavy lifting and more compatibility between tools. I expect the future to look like a range of completely separate tools for specific formats and toolchains which just happen to be compatible because they implement CNAB. We can then build a whole new set of tools that work across all of these packages, from graphical installers to documentation generation to whatever else we can think of. If that sounds interesting join the conversation around this new specifaction and lets see if it just might work.
Jul 29, 2018 · 4 minute read
Knative Build is one of the components of Knative that shipped last week.
Knative is described as a set of “essential base primitives”, one of those is an approach to describing build pipelines to run on Kubernetes.
Installing knative/build is relatively simple as long as you have
a Kubernetes cluster running at least 1.10. Handily Docker Desktop for Windows or
Mac makes it easy to get a local cluster up and running.
kubectl apply -f https://storage.googleapis.com/knative-releases/build/latest/release.yaml
With Knative Build installed we can describe our build pipelines using the new Build and BuildTemplate objects.
The documentation covers a few basic examples and
the tests folder has more. The project is early, so browsing through these
has been the best way I’ve found of discovering how to do various things. In this post I thought I’d try a few examples, making use
of the latest build functionality in Docker 18.06 and using BuildKit via Img.
Knative Build and Docker Build
First lets describe a BuildTemplate for BuildKit. Templates can be reused for different builds by defining parameters that need to be set by the Build.
Templates aren’t strictly required (see the basic examples mentioned above) but feel like a useful tool in most cases. The following template uses
the latest version of the Docker client image. We enable the experimental BuildKit builder, which isn’t stricktly required but has some nifty new features.
We also bind this to the local Docker socket, so you need to be running Docker 18.06 on the server too. Again, if you’re using Docker Desktop locally then you’re all set.
Save the following as buildkit.yaml.
apiVersion: build.knative.dev/v1alpha1
kind: BuildTemplate
metadata:
name: buildkit
spec:
parameters:
- name: IMAGE
description: Where to publish the resulting image.
steps:
- name: build
image: docker:18.06
env:
- name: DOCKER_BUILDKIT
value: "1"
args: ["build", "-t", "${IMAGE}", "."]
volumeMounts:
- name: docker-socket
mountPath: /var/run/docker.sock
volumes:
- name: docker-socket
hostPath:
path: /var/run/docker.sock
type: Socket
Let’s add that template to the cluster:
kubectl apply -f buildkit.yaml
Then we describe our build. For this I’m using kubeval but you can use source repository which provides
a Dockerfile to build from. Save the following as kubeval-buildkit.yaml:
apiVersion: build.knative.dev/v1alpha1
kind: Build
metadata:
name: kubeval-buildkit
spec:
source:
git:
url: https://github.com/garethr/kubeval.git
revision: master
template:
name: buildkit
arguments:
- name: IMAGE
value: garethr/kubeval
Finally trigger the build by submitting the Build object to the Kubernetes API.
kubectl apply -f kubeval-buildkit.yaml
We can watch the build by watching the object:
kubectl get build kubeval-buildkit -o yaml -w
For the actual build logs we need to go a little deeper. From the above output you’ll see the name of the pod. Use that in the following command
(just swap out the gztzq part) to get the build logs from Docker:
kubectl -n default logs -f kubeval-buildkit-gztzq -c build-step-build
Knative Build and Img
The above example uses the hosts Docker daemon, but if you want to run the build without you’re in luck. Img
is a “standalone, daemon-less, unprivileged Dockerfile and OCI compatible container image builder.” It’s using the same build engine, BuildKit, as
we used above with Docker 18.06. In this example we’ll need to push the resulting image to a remote repository, as it won’t show up in the local engine
when you run docker images. For that Knative Build provides some handy auth options.
Let’s create a Secret and an asscoiated ServiceAccount. The username and password want to be changed to your authentication credentials for Docker Hub.
Save this as serviceaccount.yaml:
---
apiVersion: v1
kind: Secret
metadata:
name: docker-hub
annotations:
build.knative.dev/docker-0: https://index.docker.io/v1/
type: kubernetes.io/basic-auth
stringData:
username: <your username>
password: <your password>
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: build-bot
secrets:
- name: docker-hub
We then define a new BuildTemplate for Img. Note this one has two steps rather than just one. Save the following as img.yaml:
apiVersion: build.knative.dev/v1alpha1
kind: BuildTemplate
metadata:
name: img
spec:
parameters:
- name: IMAGE
description: Where to publish the resulting image.
steps:
- name: build
image: garethr/img
args: ["build", "-t", "${IMAGE}", "."]
securityContext:
privileged: true
- name: push
image: garethr/img
args: ["push", "${IMAGE}", "-d"]
securityContext:
privileged: true
With those defined we can submit them to Kubernetes:
kubectl apply -f serviceaccount.yaml -f img.yaml
Finally we describe out build. The only changes to the above are the addition of the serviceAccountName property (so the build will have access to the Docker Hub credentials)
and swapping the buildkit template out for the img one we just defined. If you want this to work for you then you’ll need to swap out the image name to a repository
you have permissions to push to, rather than garethr/kubeval.
apiVersion: build.knative.dev/v1alpha1
kind: Build
metadata:
name: kubeval-img
spec:
serviceAccountName: build-bot
source:
git:
url: https://github.com/garethr/kubeval.git
revision: master
template:
name: img
arguments:
- name: IMAGE
value: garethr/kubeval
Save the above as kubeval-img.yaml and finally submit the build:
kubectl apply -f kubeval-img.yaml
As before we can watch the build by watching the relevant object:
kubectl get build kubeval-img -o yaml -w
And again to get at the logs we’ll rhe name of the pod. Use that in the following command
(just swap out the gztzq part) to get the build logs from Img:
kubectl -n default logs -f kubeval-img-gztzq -c build-step-build
There are a few things to note with the above:
- The
img images run as priviledged. I tried and failed to set the relevant capabilities instead but I’m sure that’s fixable
with a little more debugging
- I rebuilt the
img Docker image and pushed this to my repo. This image runs as root, due to a conflict with permissions and
the user in the original image. Again, I’m sure that’s also resolvable with a bit more spelunking.
Conclusions
The above demonstrates how to use Knative Build from what I’ve been able to pick up from the documentation and examples. This definitely
feels like a component for folks to build higher-level interfaces on. It solves some useful problems but requires a fair understanding
of Kubernetes objects to utilise and interact with today. I could certainly see the potential however for some more user-fiendly tools on top of
this in the future.
Jul 7, 2017 · 5 minute read
While at JeffConf I had a particularly
interesting conversation with Anne,
James and
Guy. Inspired by that, and
the fact James is currently writing a blog post a day, I thought I’d
have a go at writing up some of my thoughts.
I want to focus on a couple of things relevant to the evolution of
Serverless as a platform and the resulting commercial ecosystem,
namely the importance of Open Service Broker
and a bet on OpenWhisk.
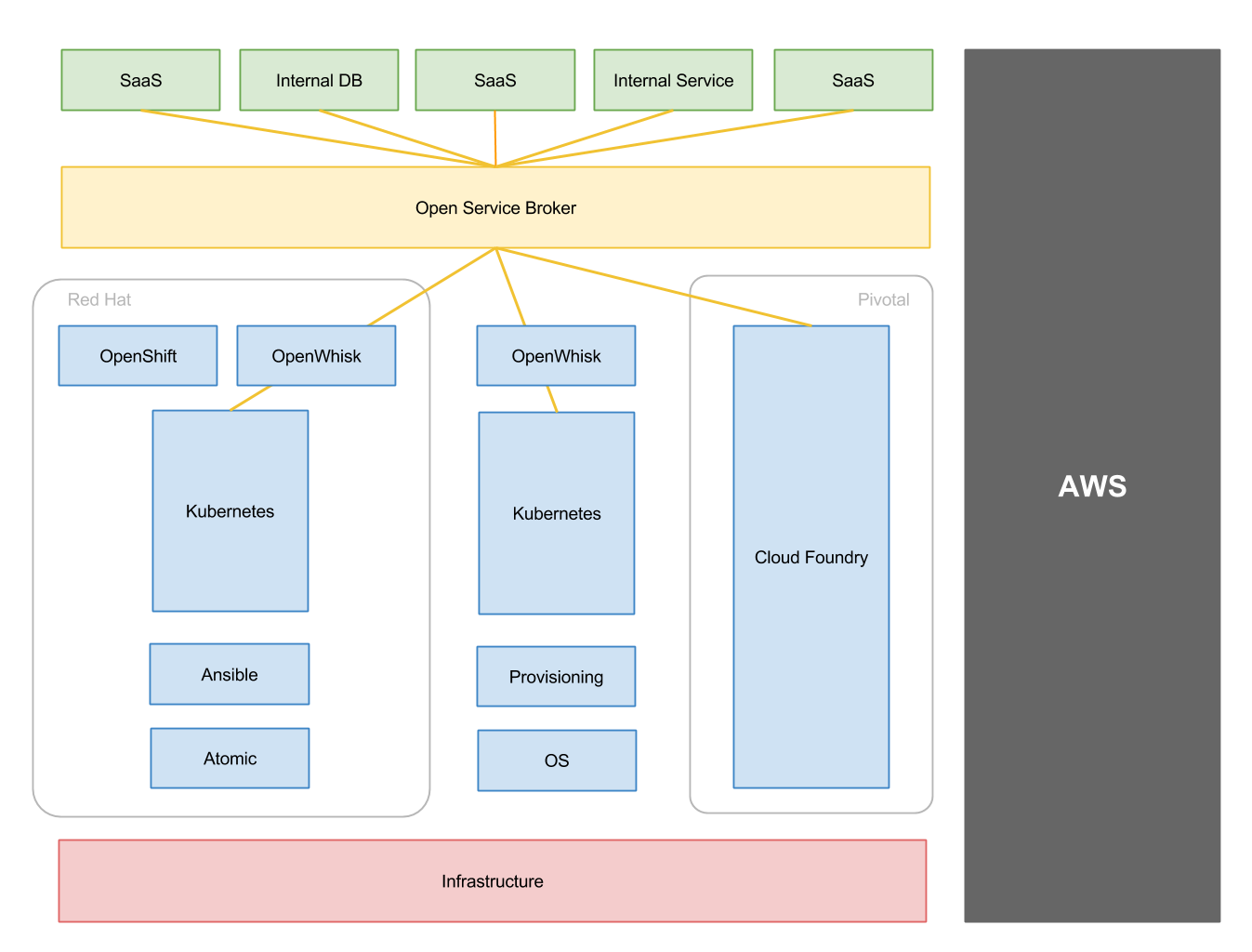
The above is a pretty high-level picture of how I think Serverless
platforms are playing out. I’ve skipped a few things from the diagram
that I’ll come back to, and I’m not trying to detail all options, just
the majority by usage, but the main points are probably:
OpenWhisk
OpenWhisk is one of a number of run-your-own-serverless platforms vying
for
attention.
My guess is it’s the one that will see actual market adoption over time.
One of the reasons for that is that Red Hat recently announced they are supporting
OpenWhisk.
Specifically they are working to run OpenWhisk on top of Kubernetes
which I see as being something that will tap into the growing number of
people and companies adopting Kubernetes in one form or another.
Kubernetes provides a powerful platform to build higher-level user
interfaces on, and I see it ending up as the default here.
There are a few things that could make this prediction much messier. One
of those is that OpenWhisk is currently in the incubator for the Apache
Foundation. CNCF has been building up a product portfolio across tools
in this space, and has a Serverless working
group. It would be a shame if
this somehow ends up with a perceived need to bless something else.
The other might be say an aquisition of Serverless Framework by Docker
Inc, or a new entrant completely.
Open Service Broker
Without supporting services to bind to, Serverless computing doesn’t look as
interesting. Although you’ll see some standalone Lambda usage it’s much
more common to see it combined with API Gateway, DynamoDB, S3, Kinesis,
etc. The catch is that these are AWS services. Azure (with Azure
Functions) and Google Cloud (with Cloud Functions) are busy building
similar ecosystems. This makes the barrier to entry for a pure
technology play (like OpenWhisk or something else) incredibly high.
AWS Services work together because they are built by the same
organisation, and integrated together via the shared AWS fabric. How can
you build that sort of level of agreement between a large number of
totally unconnected third parties? What about exposing internal services
(for instance your large Oracle on-premise cluster) to your serverless
functions? Enter Open Service Broker.
Open Service Broker has been around since the end of last
year.
It defines an API for provisioning, deprovisioning and binding services
for use by other platforms, for instance by Cloud Foundry or Kubernetes or
similar. Here’s a quick example
broker.
I think we’ll see Open Service Broker powering some powerful
higher-level user interfaces in other platforms eventually which aim to
compete directly with, for instance, the ease of binding an API Gateway
to a Lambda function in AWS. Especially if you’re a service provider I’d
get a march on the competition and start looking at this now. This is
also a potential avenue for the other cloud providers to expand on there
claims of openness. I’d wager on us seeing Azure services available over
Open Service Broker for instance.
- Anyone but Amazon will be real - on both the buyer side (a little) and
the vendor side (a lot) you’ll see a number of unlikely
collaborations between competitors at the technology level.
- Open Source is a fundamental part of any AWS competition. AWS hired
some great open source community focused people recently so expect to
see them try to head that threat off if it gets serious
- The fact Amazon provides the entire stack AND runs a chunk of the
infrastructure for the other options help explains why people (again
especially other vendors) fear AWS.
- Both Pivotal and Red Hat will be in the mix when it comes to hosted
serverless platforms, with CloudFoundry and OpenShift (powered by
OpenWhisk) respectively.
- The stack in the middle of some OS, some provisioning, Kubernetes and
OpenWhisk will have lots of variants, including from a range of
vendors. Eventually some might focus on serverless, but for others
it will be simply another user interface atop a lower-level
infrastructure play.
- If you’re thinking “But Cloud Foundry isn’t serverless?” then you’re
not paying attention to things like the recent release of Spring Functions.
- In theory Azure and Google Cloud could end up playing in the same place
as AWS. But with the lead AWS Lambda has in the community that is going
to take something more than just building a parallel ecosystem. I could
totally see Azure embracing OpenWhisk as an option in Azure Functions,
in the way Azure Container Service is happy to provide multiple
options.
Overall I’ll be interested to see how this plays out, and whether my
guesses above turn out to be anywhere near right. There will be a lot of
intermediary state, with companies large and small, existing and new,
shipping software. And like anything else it will take time to stablise,
whether to something like the above or something else entirely.
I feel like the alternative to the above is simply near total domination
by 1 or maybe 2 of the main cloud providers, which would be less
interesting to guess about and made for a shorter blog post.
Jun 26, 2017 · 5 minute read
I’ve been playing around building a few Kubernetes developer tools at
the moment and a few of those led me to the question; how do I validate
this Kubernetes resource definition? This simple question led me through
a bunch of GitHub issues without resolution, conversations with folks
who wanted something similar, the OpenAPI specification and finally to
what I hope is a nice resolution.
If you’re just after the schemas and don’t care for the details just
head on over to the following GitHub repositories.
OpenShift gets a separate repository as it has an independent version
scheme and adds a number of additional types into the mix.
But why?
It’s worth asking the question why before delving too far into the
how. Let’s go back to the problem; I have a bunch of Kubernetes resource
definitions, lets say in YAML, and I want to know if they are valid?
Now you might be thinking I could just run them with kubectl? This
raises a few issues which I don’t care for in a developer tool:
- It requires
kubectl to be installed and configured
- It requires
kubectl to be pointed at a working Kubernetes cluster
Here are a few knock-on effects of the above issues:
- Running what should be a simple validate step in a CI system now
requires a Kubernetes cluster
- Why do I have to shell out to something and parse it’s output to validate
a document, for instance if I’m doing it in the context of a unit test?
- If I want to validate the definition against multiple versions of
Kubernetes I need multiple Kubernetes clusters
Hopefully at this point it’s clear why the above doesn’t work. I don’t
want to have to run a boat load of Kubernetes infrastructure to validate
the structure of a text file. Why can’t I just have a schema in a
standard format with widespread library support?
From OpenAPI to JSON Schema
Under-the-hood Kubernetes is all about types. Pods,
ReplicationControllers, Deployments, etc. It’s these primatives that
give Kubernetes it’s power and shape. These are described in the
Kubernetes source code and are used to generate an OpenAPI description of
the Kubernetes HTTP API. I’ve been spelunking here before with some work on
generating Puppet types from this same specification.
The latest version of OpenAPI in fact already contains the type
information we seek, encoded in a superset of JSON
Schema in the definitions key. This is
used by the various tools which generate clients from that definition.
For instance the official python client doesn’t know about these types
directly, it all comes from the OpenAPI description of the
API. But how
do we use those definitions separately for our own nefarious
validation purposes? Here’s a quick sample of what we see in the 50,000
line-long OpenAPI definition file
- definitions: {
io.k8s.api.admissionregistration.v1alpha1.AdmissionHookClientConfig: {
description: "AdmissionHookClientConfig contains the information to make a TLS connection with the webhook",
required: [
"service",
"caBundle"
],
properties: {
caBundle: {
description: "CABundle is a PEM encoded CA bundle which will be used to validate webhook's server certificate. Required",
type: "string",
format: "byte"
},
service: {
description: "Service is a reference to the service for this webhook. If there is only one port open for the service, that port will be used. If there are multiple ports open, port 443 will be used if it is open, otherwise it is an error. Required",
$ref: "#/definitions/io.k8s.api.admissionregistration.v1alpha1.ServiceReference"
}
}
},
The discussion around wanting JSON Schemas for Kubernetes types has
cropped up in a few places before, there are some useful comments on this
issue for
instance. I didn’t find a comprehensive solution however, so set out on
a journey to build one.
OpenAPI2JsonSchema
The tooling I’ve build for this purpose is called
openapi2jsonschema.
It’s not Kubernetes specific and should work with other OpenAPI
specificied APIs too, although as yet I’ve done only a little testing of
that. Usage of openapi2jsonschema is fairly straightforward, just
point it at the URL for an OpenAPI definition and watch it generate a
whole bunch of files.
openapi2jsonschema https://raw.githubusercontent.com/kubernetes/kubernetes/master/api/openapi-spec/swagger.json
openapi2jsonschema can generate different flavours of output, useful
for slightly different purposes. You probably only need to care about
this if you’re generating you’re own schemas or you want to work
completely offline.
- default - URL referenced based on the specified GitHub repository
- standalone - de-referenced schemas, more useful as standalone documents
- local - relative references, useful to avoid the network dependency
The build script
for the Kubernetes schemas is a simple way of seeing this in practice.
Published Schemas
Using the above tooling I’m publishing Schemas for Kubernetes, and for
OpenShift, which can be used directly from GitHub.
As an example of what these look like, here are the links to the latest deployment schemas for
1.6.1:
A simple example
There are lots of use cases for these schemas, although they are primarily
useful as a low-level part of other developer workflow tools. But at a most
basic level you can validate a Kubernetes config file.
Here is a quick example using the Python jsonschema
client and an invalid deployment
file:
$ jsonschema -F "{error.message}" -i hello-nginx.json
1.5.1-standalone/deployment.json
u'template' is a required property
What to do with all those schema?
As noted these schemas have lots of potential uses for development
tools. Here are a few ideas, some of which I’ve already been hacking on:
- Demonstrating using with the more common YAML serialisation
- Testing tools to show your Kubernetes configuration files are valid,
and against which versions of Kubernetes
- Migration tools to check your config files are still valid against
master or beta releases
- Integration with code editors, for instance via something like Schema
Store
- Validation of Kubernetes configs generated by higher-level tools, like
Helm, Ksonnet or Puppet
- Visual tools for crafting Kubernetes configurations
- Tools to show changes between Kubernetes versions
If you do use these schemas for anything please let me know, and I’ll
try and keep them updated with releases of Kubernetes and OpenShift. I
plan on polishing the openapi2jsonschema tool when I get some time,
and I’d love to know if anyone uses that with other OpenAPI compatible
APIs. And if all you want to do is validate your Kubernetes
configuration and don’t care too much about what’s happening under the
hood then stick around for the next blog post.
May 29, 2017 · 5 minute read
Everyone has little scripts that want running on some schedule. I’ve
seen entire organisations basically running on cron jobs. But for all
the simplicity of cron it has a few issues:
- It’s a per-host solution, in a world where hosts might be short-lived
or unavailable for some other reason
- It requires a fully configured and secured machine to run on, which
comes with direct and indirect costs
There are a variety of distributed cron solutions around, but each
adds complexity for what might be a throw-away script. In my view this
is the perfect usecase for trying out AWS Lambda, or other Serverless
platforms. With a Serverless platform the above two issues go away from
the point-of-view of the user, they are below the level of abstraction
of the provided service. Lets see a quick example of doing this.
Apex and Lambda
There are a number of frameworks and tools for helping deploy Serverless
functions for different platforms. I’m going to use Apex
because I’ve found it provides just enough of a user interface without
getting in the way of writing a function.
Apex supports a wide range of different languages, and has lots of
examples which
makes getting started relatively easy. Installation is
straightforward too.
A sample function
The function isn’t really relevant to this post, but I’ll include one
for completeness. You can write functions in officially supported
languages (like Javascript or Python) or pick one of the languages
supported via a shim in Apex. I’ve been writing Serverless functions in
Go and Clojure recently, but I prefer Clojure so lets use that for now.
(ns net.morethanseven.hello
(:gen-class :implements [com.amazonaws.services.lambda.runtime.RequestStreamHandler])
(:require [clojure.java.io :as io]
[clojure.string :as str])
(:import (com.amazonaws.services.lambda.runtime Context)))
(defn -handleRequest
[this input-stream output-stream context]
(let [handle (io/writer output-stream)]
(.write handle (str "hello" "world"))
(.flush handle)))
This would be saved at
functions/hello/src/net/morethanseven/hello.clj, and the Apex
project.json file should point at the function above:
{
"runtime": "clojure",
"handler": "net.morethanseven.hello::handleRequest"
}
You would also need a small configuration file at functions/hello/project.clj:
(defproject net.morethanseven "0.1.0-SNAPSHOT"
:description "Hello World."
:dependencies [[com.amazonaws/aws-lambda-java-core "1.1.0"]
[com.amazonaws/aws-lambda-java-events "1.1.0" :exclusions [
com.amazonaws/aws-java-sdk-s3
com.amazonaws/aws-java-sdk-sns
com.amazonaws/aws-java-sdk-cognitoidentity
com.amazonaws/aws-java-sdk-kinesis
com.amazonaws/aws-java-sdk-dynamodb]]
[org.clojure/clojure "1.8.0"]]
:aot :all)
The above is really just showing an example of how little code a
function might contain, the specifics are relevant only if you’re
intersted in Clojure. But imagine the same sort of thing for your
language of choice.
Infrastructure
The interesting part (hopefully) of this blog post is the observation
that using AWS Lambda doesn’t mean you don’t need any infrastructure or
configuration. The good news is that, for the periodic job/cron usecase
this infrastructure is fairly standard between jobs.
Apex has useful integration with Terraform
to help manage any required infrastructure too. We can run the following
two commands to provision and then manage our infrastructure.
apex infra init
apex infra deploy
Doing so requires us to write a little Terraform code. First we need
some variables, we’ll invclude this in infrastructure/variables.tf:
variable "aws_region" {
description = "AWS Region Lambda function is deployed to"
}
variable "apex_environment" {
description = "Apex configured environment. Auto provided by 'apex infra'"
}
variable "apex_function_role" {
description = "Provisioned Lambda Role ARN via Apex. Auto provided by 'apex infra'"
}
variable "apex_function_hub" {
description = "Provisioned function 'hub' ARN information. Auto provided by 'apex infra'"
}
variable "apex_function_hub_name" {
description = "Provisioned function 'hub' name information. Auto provided by 'apex infra'"
}
And then we need to describe the resources for our cron job in
infrastructure/main.tf:
resource "aws_cloudwatch_event_rule" "every_five_minutes" {
name = "every-five-minutes"
description = "Fires every five minutes"
schedule_expression = "rate(5 minutes)"
}
resource "aws_cloudwatch_event_target" "check_hub_every_five_minutes" {
rule = "${aws_cloudwatch_event_rule.every_five_minutes.name}"
target_id = "${var.apex_function_hub_name}"
arn = "${var.apex_function_hub}"
}
resource "aws_lambda_permission" "allow_cloudwatch_to_call_hub" {
statement_id = "AllowExecutionFromCloudWatch"
action = "lambda:InvokeFunction"
function_name = "${var.apex_function_hub_name}"
principal = "events.amazonaws.com"
source_arn = "${aws_cloudwatch_event_rule.every_five_minutes.arn}"
}
Here we’re running the job every 5 minutes, but it should be relatively
easy to see how you can change that frequency. See the Terraform and AWS
Lambda documentation for all the possible options.
On complexity, user interface and abstractions
The above is undoutedly powerful, and nicely solves the described
probles with using Cron. However it’s not all plain sailing I feel
with Serverless as a Cron replacement.
Let’s talk about complexity. If I can make the assumptions that:
- The underlying host I was going to run my cron job on host is well managed,
potentially by another team in my organisation
- Hosts don’t suffer downtime, or if they do it’s occasional and they
are brough back up quickly
Then I can just use cron. And the interface to cron looks something more
like:
*/5 * * * * /home/garethr/run.sh
I still had to write my function (the Clojure code above) but I
collapsed the configuration of three distinct AWS resources and the use of a
new tool (Terraform) into a one-line crontab entry. You might have
provisioned that cron job using Puppet or Chef which adds a few lines
and a new tool, which sits somewhere between hand editing and the above
example.
This is really a question of user interface design and abstractions.
On one hand Serverless provides a nice high-level shared abstraction for
developers (the function). On another Serverless requires a great deal
of (virtual) infrastructure, which at the moment tends not to be abstracted
from the end-user. In the simple case above I had to care about
aws_cloudwatch_event_targets, aws_cloudwatch_event_rules and
aws_lambda_permissions. The use of those non-abstract resources all
couples my simple cron example to a specific platform (AWS) when the
simple function could likely run on any Serverless platform that
supports the JVM.
Serverless, not Infrastructureless
I’m purposefully nit-picking with the above example. Serverless does
provide a more straightforward cron experience, mainly because it’s
self-contained. But the user interface even for simple examples is still
very raw in many cases. Importantly, in removing the concept of ervers,
we don’t appear to have removed the need to configure infrastructure,
which I think is what many people thing of when they hope to be rid of
servers in the first place.
May 26, 2017 · 9 minute read
While reviewing 100s of proposals for upcoming conferences (Velocity EU and
PuppetConf) I tweeted the
following, which
seemed to get a few folks interest.
I should write a blog post on “conference talk submissions for
vendors/consultants”. Rule one: own your bias
This reply in
particular pushed me over the edge into actually writing this post:
Would love to hear advice, been told more than once a talk was rejected
since I work for a vendor, even though my talk was not a pitch.
Writing something up felt like it might be useful to a few folks so here
goes. This is but one persons opinion, but I at least have some relevant
experience:
- I’ve worked for a software vendor for about 3 years
- Before that I worked for the UK Government, and before that various
SaaS companies, in-house software teams and very briefly myself
- I’ve helped out on the programme committee or similar for a variety of
events going back a bunch of years; Velocity, PuppetConf, Lisa,
Devopsdays, QCon
- I’ve been lucky enough to speak at a wide range of events in lots of
different places
Some of the following advice is pretty general, if you’re interested in
speaking at software conferences (at least those I’ve seen or spoken at)
then hopefully much of this is relevant to you. But I also want to focus on
people working for a software vendor. I think that’s particularly
relevant as more and more traditional vendors court the open source
community and software developers inparticular, and roles like
developer evangelist see lots of people moving from more practioner
roles to work vendor-side.
Learn to write a good proposal
My main experience with speaking at conferences, or helping currate
content, is via a call-for-proposals. The conference will have some
sort of theme or topic, set a date, and see what content is submitted.
Their are a variety of oft-made points here about sponsoring to get a
talk slot, or submitting early, or approaching the organisers, but in my
experience the best bet is to write a really good proposal around a good
idea. That’s obviously easier said that done, but it’s not as hard as
you may think.
- Introduce the problem you’re talking about, but don’t make
this the whole proposal.
- State in the proposal what you’re going to talk about. Be specific.
Don’t say “an open source tool” when you mean a specific tool which
has a name. Don’t hide the details of the talk because you intend to
reveal them when presenting.
- Include explicitly what the audience will do or be able to do
differently after seeing the talk. Go so far as to say “after this
talk attendee will…”
- Novely really helps, as long as the topic is interesting and relevant.
Given 100 proposals about deploying your web application with Docker,
the one that says “and we do this for the International Space Station”
is getting picked.
- If you know this is going to be a popular topic for other proposals
then you also need to confince the CFP committee why you’re the best
person to present it.
- Liberally use bullet points. This might be a personal thing but if I’m
reading 200+ proposals making it quick to read helps get your point
across.
Unless you write a good proposal around an interesting idea you probably
won’t be accepted whether you’re a software vendor or not. Try get
feedback on your proposals, especially from folks who have previously
spoken at the event you’re hoping to present at.
Appreciate you’re selling something
If you work for a software vendor your job is to sell software. Not
everyone likes that idea, but I think at least for the purposes of this
blog post it stands true. It doesn’t matter if you’re an evangelist
reporting into Marketing, or a software developer in Engineering or
anything else - you stand to gain directly or indirectly from people
purchasing your product. From the point of view of a conference you are
thoroughly compromised when it comes to talking about your product
directly. This can be disheartening as you likely work at the vendor
and want to talk at the conference because you’re genuinely interested,
even evangelical, about the product. You need to own that bias - there
really is no way around it.
If you work for a vendor, and the CFP committee even thinks the proposal
is about that product, you’ll probably not be given the benefit of
doubt.
And the answers is…
Probably the worst example of vendor talks that do sometimes get
accepted go something like this:
- Introduce a problem people can relate to
- Show some (probably open source) options for solving, focusing on the
large integration cost of tying them together
- Conclude with the answer being the vendors all-in-one product
I think for expo events or for sponsored slots this approach is totally
valid, but for a CFP it bugs me:
- The proposal probably didn’t explain that the the answer was the
commercial product sold by the vendor
- The talk is unlikely to cover like-for-like competition, for instance
it’s probably not going to spend much time referring to direct
commercial competitors
- As noted above, the presented is thoroughly biased, which doesn’t make
for a great conference talk
Please don’t do this. It’s a easy trap to fall into, mainly because you
hopefully genuinely believe in the product you’re talking about and the
problem you’re solving. If you really want talks like this try and
encourage your customers to give then - a real-world story version of
this is much more interesting.
Talk about the expertise rather than the product
It’s not all doom for those working for software vendors and wanting to
talk at conferences. The reality is that while you’re working on a
discrete product you’re also likely spending a lot of time thinking about
a specific domain. I spent a bunch of years using Puppet as a product,
but I’ve spent more time while working at Puppet thinking about the
nature of configuration, and about wildly heterogenuous systems. When I
worked for the Government I interacted with a handful of departments and
projects. At Puppet I’ve spoken with 100s of customers, and read trip
reports on meetings with others. Working for a vendor gives you a
different view of what’s going on, especially if you talk to people from
other departments.
In my experience, some of the best talks from those working for software
vendors can be quite meta, theoretical or future facing. You have the
dual benefit of working in a singular domain (so you can do deep) and
hopefully having access to lots customers (so you can go broad).
As someone working for a vendor, a big part of my job is designing and
building new features or new products. I’ve regularly found giving talks
(including the time taken to think about the topic and put together the
demos and slides) to be a great design tool. Assuming you’re already
doing research like this, even in the background, pitching a talk on the
subject has a few advantages:
- It starts you writing for a public audience early in the design
process
- The talk being accepted, and the feedback from the talk, provide early
input into the design process
- The talk (or published slides) can encourage people thinking about
similar things to get in touch
You can see this if you flick through talks I’ve given over the past few
years. For instance What’s inside that
container?
and more recently Security and the self-contained unit of software
provide some of the conceptual underpinnings for
Lumogon. And The Dockerfile explosion - and the need for higher-level tools
talk I gave at DockerCon led to the work on Puppet Image
Build.
These talks all stand alone as (hopefully) useful and interesting
presentations, but also serve a parallel internal purpose which
importantly doesn’t excert the same bias on the content.
Some good examples
The above is hopefully useful theory, but I appreciate some people
prefer examples. The following include a bunch of talks I’ve given at
various conference, with a bit of a rationale. I’ve also picked out a
few examples of talks by other folks I respect that work at software
vendors and generally give excellent talks.
A great topic for most vendors to talk about at suitable conferences is
how they approach building software. I spoke about In praise of slow
(Continuous
Delivery)
at Pipeline conference recently, about how Puppet (and other vendors)
approach techniques like feature flags, continuous delivery and
versioning but for packaged software. That had novelty, as well as being
relevant to anyone involved with an open source project.
Probably my favourite talk I’ve given in the last year,
The Two Sides to Google Infrastructure for Everyone Else
looks at SRE, and infrastructure from two different vantage points.
This talk came directly from spending time with the container folks on
one hand, and far more traditional IT customers on the other, and
wondering if they meet in the middle.
Charity Majors is the CEO at Honeycomb and likes databases a lot more
than I do. The talk Maslows Hierachy of Database Needs
is just solid technical content from an expert on the subject. Closer to
the Honeycomb product is this talk
Observability and the Glorious Future,
but even this avoids falling into the trap described above and stays
focused on generally applicable areas to consider.
Jason Hand from VictorOps has given a number of talks about ChatOps,
including this one entitled Infrastructure as Conversation.
Note that some of the examples use VictorOps, but the specific tool
isn’t the point of the talk. The abstract on the last slide is also a
neat idea.
Bridget Kromhout works for Pivotal, the
folks behind Cloud Foundry amongst other things. But she invariably
delivers some of the best big picture operations talks around. Take a
couple of recent examples I Volunteer as Tribute - the Future of Oncall
and Ops in the Time of Serverless Containerized Webscale.
Neither talk is about a specific product, instead both mix big picture
transformation topics with hard-earned ops experience.
As a final point, all of those examples have interesting titles, which
comes back to the first point above. Make content that people really want
to listen to first, and if you’re a vendor own your biases.
Mar 29, 2017 · 3 minute read
Tomorrow at KubeCon in Berlin I’m running a birds-of-a-feather session to talk
about Kubernetes configuration. Specifically we’ll be talking about whether
Kubernetes configuration benefits from a domain specific language. If you’re
at the conference and this sounds interesting come along.
The problem
The fact the programme committee accepted the session proposa is hopefully a good
indication that at least some other people in the community think this is an
interesting topic to discuss. I’ve also had a number of conversations in person
and on the internet about similar areas.
There are a number of other traces of concerns with using YAML as the main user
interface to Kubernetes configuration. This comment from Brian Grant of Google on the
Kubernetes Config SIG mailing list for instance:
We’ve had a few complaints that YAML is ugly, error prone, hard to read, etc.
Are there any other alternatives we might want to support?
And this one from Joe Beda,
one of the creators of Kubernetes:
I want to go on record: the amount of yaml required to do anything in k8s is a
tragedy. Something we need to solve. (Subtweeting HN comment)
This quote from the Borg, Omega and Kubernetes paper in ACM Queue, Volume 14, issue 1
nicely sums up my feelings:
The language to represent the data should be a simple, data-only format
such as JSON or YAML, and programmatic modification of this data should
be done in a real programming language
This quote also points at the problem I see at the moment. The configuration and the
management of that configuration are separate but related concerns. Far too many
people couple these together, ultimately moving all of the management complexity
onto people. That’s a missed opportunity in my view. The Kubernetes API is my
favourite think about the project, I’ve waxed lyrical about it allowing for
different higher-level user interfaces for different users to all interact
on the same base platform. But treating what is basically the wire format
as a user interface is just needlessly messy.
But what advantages do we get using a programming language to modify the data?
For me it comes down to:
- Avoiding repetition
- Combining external inputs
- Building tools to enforce correctness (linting, unit testing, etc.)
- The abililty to introduce abstractions
It’s the last part I find most compelling. Building things to allow others
to interact with a smaller domain specific abstraction is one way of scaling
expertise. The infrastructure as code space I’ve been involved in has lots of
stories to tell around different good (and bad) ways of mixing data with code,
but the idea that data on it’s own is enough without higher-level abstractions
doesn’t hold up in my experience.
What can I use instead?
Lukily various people at this point have build tools in this space. I’m not sure
could or should be a single answer to the question (whether there should be a
default is a harder question to answer) but the following definitely all show
what’s possible.
Obviously I wrote one of these
so I’m biased but different tools work for different people and in different
contexts. For example Skuber looks nice but I mainly don’t like Scala. And
I’ve been using Jsonnet for Packer templates recently with success, so I’m
very interested in kubecfg which provides a nice Kubernetes wrapper to that
tool.
Ultimately this is still a developing space, but compared to a year ago it is
now definitely moving. For me, I hope the default for managing Kubernetes
configuration slowly but surely switches away from just hand rolling data.
Towards what, only time and people reporting what works for them will tell.
Jan 1, 2017 · 2 minute read
One of the many things I did some work on while at
GDS back in 2013 was the Government Service Design
Manual. This was intended to be a
central resource for teams across (and outside) Government about how to
go about building, designing and running modern internet-era services.
It was a good snapshot of opinions from the people that made up GDS on a
wide range of different topics. Especially for the people who spent time
in the field with other departments, having an official viewpoint published
publicly was hugely helpful.
Recently the Service Manual got a bit of a relaunch
but unfortunately this involved deleting much of the content about
operations and running a service. Even more unfortunately the service
manual is now described as something that:
exists to help people across government build services that meet the
Digital Service Standard and prepare for service assessments.
So in basic terms it’s refocusing on helping people pass the exam rather
than being all about learning. Which is a shame. Compare that with the
original intent:
Build services so good that people prefer to use them
However, all that content is not lost. Luckily the content is archived on GitHub
and was published under the terms of the Open Government License
which allows for anyone to “copy, publish, distribute and transmit the Information”.
So I’m choosing to republish a few of the pieces I wrote and found
useful when talking to and assisting other Government departments. These
represent an interesting snapshot from a few years ago, but I think
mainly stand the test of time, even if I’d change a few things if I
wrote them today.
Jan 1, 2017 · 4 minute read
This post was originally written as part of the Government Service
Design Manual while I was working for the UK Cabinet Office. Since my
original in 2013 it was improved upon by several
others
I’m republishing it here under the terms of the Open Government
licence.
Devops is a cultural and professional movement in response to the
mistakes commonly made by large organisations. Often organisations will
have very separate units for:
- development
- quality assurance
- operations business
In extreme cases these units may be:
- based in different locations
- work for different organisations
- under completely different management structures
Communication costs between these units, and their individual
incentives, leads to slow delivery and a mountain of interconnected
processes.
This is what Devops aims to correct. It is not a methodology or
framework, but a set of principles and a willingness to break down
silos. Specifically Devops is all about:
Culture
Devops needs a change in attitude so shared ownership and collaboration
are the common working practices in building and managing a service.
This culture change is especially important for established
organisations.
Automation
Many business processes are ready to be automated. Automation removes
manual, error-prone tasks – allowing people to concentrate on the
quality of the service. Common areas that benefit from automation are:
- release management (releasing software)
- provisioning
- configuration management
- systems integration
- monitoring
- orchestration (the arrangement and maintenance of complex computer
systems)
- testing
Measurement
Data can be incredibly powerful for implementing change, especially when
it’s used to get people from different groups involved in the quality of
the end-to-end service delivery. Collecting information from different
teams and being able to compare it across former silos can implement
change on its own.
Sharing
People from different backgrounds (ie development and operations) often
have different, but overlapping skill sets. Sharing between groups will
spread an understanding of the different areas behind a successful
service, so encourage it. Resolving issues will then be more about
working together and not negotiating contracts.
Why Devops
The quality of your service will be compromised if teams can’t work
together, specifically:
- those who build and test software
- those that run it in production
The root cause is often functional silos; when one group owns a specific
area (say quality) it’s easy for other areas to assume that it’s no
longer their concern.
This attitude is toxic, especially in areas such as:
- quality
- release management
- performance
High quality digital services need to be able to adapt quickly to user
needs, and this can only happen with close collaboration between
different groups.
Make sure the groups in your team:
- have a shared sense of ownership of the service
- have a shared sense of the problem
- develop a culture of making measurable improvements to how things work
Good habits
Devops isn’t a project management methodology, but use these good habits
in your organisation. While not unique to Devops, they help with
breaking down silos when used with the above principles:
- cross-functional teams – make sure your
teams are made up of people from different functions (this helps with
the team owning the end-to-end quality of service and makes it easier to
break down silos)
- widely shared metrics – it’s important
for everyone to know what ‘good’ looks like so share high and low
level metrics as widely as possible as it builds understanding
- automating repetitive tasks – use software development to automate
tasks across the service as it:
- encourages a better understanding of the whole service
- frees up smart people from doing repetitive manual tasks
- post-mortems – issues will happen so it’s critical that everyone
across different teams learns from them; running post-mortems (an
analysis session after an event) with people from different groups is a
great way of spreading knowledge
- regular releases
– the capacity for releasing software is often limited in siloed
organisations, because the responsibilities of the different parts of
the release are often spread out across teams – getting to a point
where you can release regularly (even many times a day) requires extreme
collaboration and clever automation
Warning signs
Like agile, the term Devops is often used for marketing or promotional
purposes. This leads to a few common usages, which aren’t necessarily in
keeping with what’s been said here. Watch out for:
- Devops tools (nearly always marketing)
- a Devops team (in many cases this is just a new silo of skills and
knowledge)
- Devops as a job title (you wouldn’t call someone “an agile”)
Further reading
Jan 1, 2017 · 6 minute read
This post was originally written as part of the Government Service
Design Manual while I was working for the UK Cabinet Office. Since my
original in 2013 it was improved upon by several
others
I’m republishing it here under the terms of the Open Government
licence.
The Digital by Default standard
says that organisations should (emphasis on operate added):
Put in place a sustainable multidisciplinary team that can design, build
and operate the service, led by a suitably skilled and senior service manager
with decision-making responsibility.
This implies a change to how many organisations have traditionally run services,
often with a team or organisation building a service separate from the one running it.
This change however does not mean ignoring existing good practice when it comes to service
management.
Agile and service management
The principles of IT service management (ITSM) and those of agile do not necessarily
conflict – issues can arise however when organisations implement rigid processes
without considering wider service delivery matters, or design and build services
without thinking about how they will be operated.
The agile manifesto makes the case for:
- Individuals and interactions over processes and tools
- Working software over comprehensive documentation
- Customer collaboration over contract negotiation
- Responding to change over following a plan
It is too easy to position service management as opposed to agile as
traditional service management practices can be viewed as focusing on processes, tools,
documentation, planning and contract negotiation – the items on the right hand
side of the points above.
However, the agile manifesto goes on to say:
That is, while there is value in the items on the right, we
value the items on the left more.
To build and run a successful service you will need to work on suitable
processes and manage third party relationships. Using existing service management
frameworks (especially as a starting point) is one approach to this problem.
ITIL
ITIL (the Information Technology Infrastructure
Library) is one such framework. ITIL does a particularly good job of facilitating shared
language. For instance it’s definition of a service is:
A service is a means of delivering value to customers by facilitating outcomes
customers want to achieve.
The current version of ITIL currently provides 5 volumes and 26 processes
describing in detail various aspects of service management:
Service Strategy
- IT service management
- Service portfolio management
- Financial management for IT services
- Demand management
- Business relationship management
Service Design
- Design coordination
- Service Catalogue management
- Service level management
- Availability management
- Capacity Management
- IT service continuity management
- Information security management system
- Supplier management
Service Transition
- Transition planning and support
- Change management
- Service asset and configuration management
- Release and deployment management
- Service validation and testing
- Change evaluation
- Knowledge management
Service Operation
- Event management
- Incident management
- Request fulfillment
- Problem management
- Identity management
Continual Service Improvement
Functions
ITIL also describes four functions that should cooperate together to form
an effective service management capability.
- Service operations
- Technical management
- Application management
- Operations management
The importance of implementation
The above processes and functions make for an excellent high level list of topics
to discuss when establishing an operating model for your service, whether
or not you adopt the formal methods. In many cases if you have well understood,
well established and well documented processes in place for all of the above
you should be in a good position to run your service.
When looking to combine much of the rest of the guidance on the service manual
with ITIL or other service management frameworks it is important to challenge
existing implementations. This is less about the actual implementation and more often
about the problems that implementation was designed to originally solve.
An example – service transition
As an example ITIL talks a great deal about Service Transition – getting working functionality
into the hands of the users of the service. This is a key topic for The Digital Service Standard
too which says that teams should:
Make sure that you have the capacity and technical flexibility to update and
improve the service on a very frequent basis.
GOV.UK for instance made more than 100 production releases
during its first two weeks after launch.
This high rate of change tends to challenge existing processes designed for a
slower rate of change. If you are releasing your service every month or every 6 months
then a manual process (like a weekly or monthly in-person change approval board or CAB) may be
the most suitable approach. If you’re releasing many times a day then the approach to how
change is evaluated, tested and managed tends towards being more automated. This
moves effort from occasional but manual activities to upfront design and automation
work. More work is put in to assure the processes rather than putting all the effort
into assuring a specific transition.
Service management frameworks tend to acknowledge this, for instance ITIL has a
concept of a standard change (something commonly done, with known risks
and hence pre-approved), but a specific implementation in a given organisation
might not.
Other frameworks exist
It is important to note that other service management frameworks and standards
exist, including some that are of a similar size and scope to ITIL:
Many organisations also use smaller processes and integrate them together.
The needs of your service and organisation will determine what works best for you.
Problematic concepts
Some traditional language tends to cause some confusion when discussing service
management alongside agile. It’s generally best to avoid the following terms when possible,
although given their widespread usage this isn’t always possible. It is however worth
being aware of the problems these concepts raise.
Projects
Projects tend to imply a start and an end. The main goal of project work is to
complete it, to reach the end. Especially for software development the project can
too often be viewed as done when the software is released. What happens after that
is another problem entirely – and often someone else’s problem.
However when building services the main goal is to meet user needs
These needs may change over time, and are only met by software that is running in
production and available to those users.
This doesn’t mean not breaking work down into easily understandable parts, but stories,
sprints and epics are much more
suited to agile service delivery.
Business as usual
The concept of business as usual also clashes with a model of continuous
service improvement. It immediately brings to mind before and after
states, often with the assumption that change is both much slower and
more constrained during business as usual. In reality, until you put your
service in the hands of real users as part of an alpha
or beta you won’t have all the information
needed to build the correct service. And even once you pass the live standard
you will be expected to:
continuously update and improve the service on the basis of user feedback,
performance data, changes to best practice and service demand
Further reading